Introducció a les LSTM
Les Xarxes de Memòria a Llarg i Curt Termini (LSTM) són un tipus especial de Xarxes Neuronals Recurrents (RNN) dissenyades per abordar el problema de la dependència a llarg termini. Les LSTM són capaces de recordar informació durant períodes de temps més llargs i són molt efectives en tasques com el processament del llenguatge natural, la predicció de sèries temporals i altres aplicacions seqüencials.
Conceptes Clau
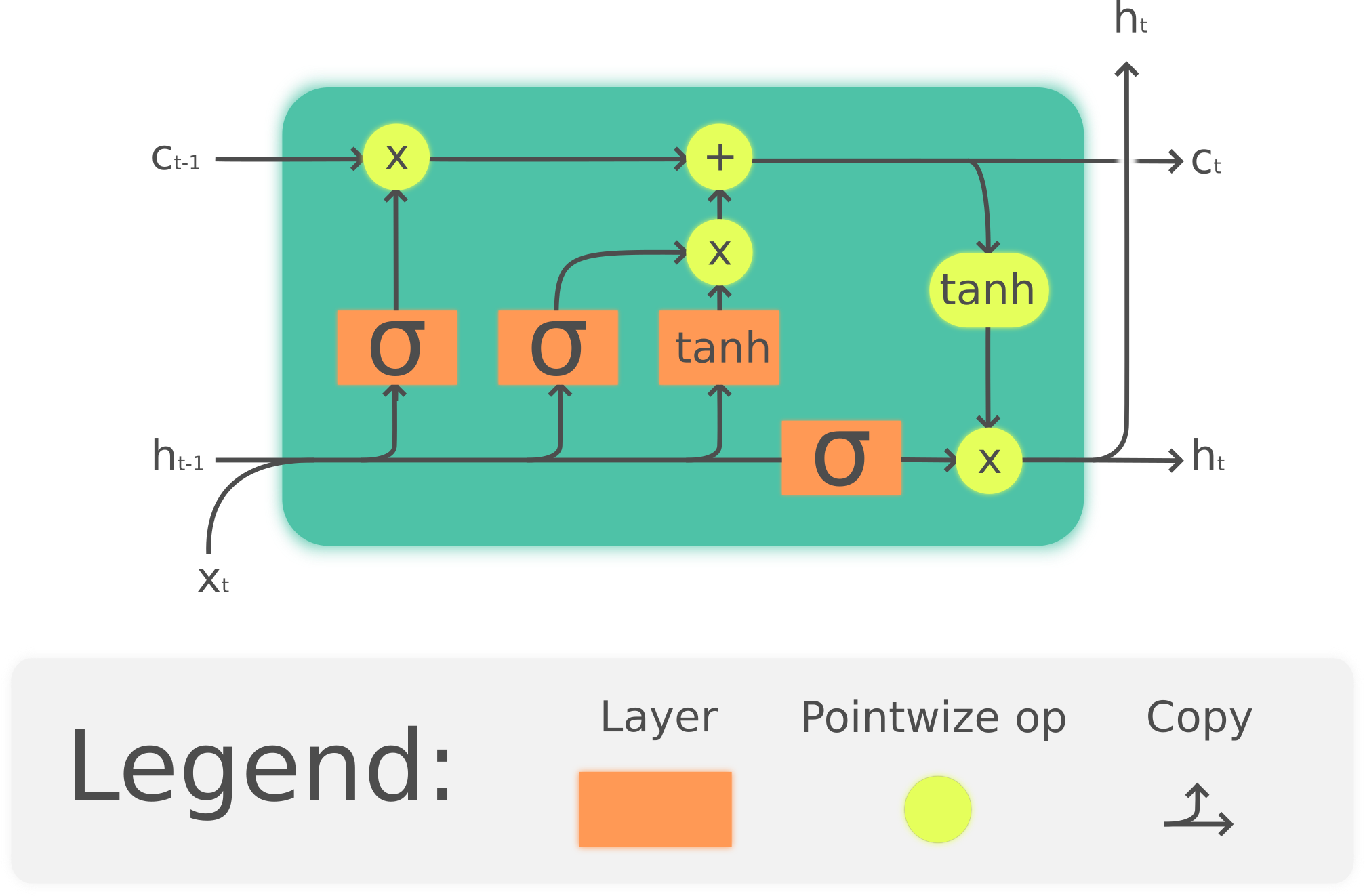
- Cèl·lula LSTM: La unitat bàsica d'una xarxa LSTM que conté una memòria a llarg termini i una memòria a curt termini.
- Portes (Gates): Mecanismes que controlen el flux d'informació dins i fora de la cèl·lula LSTM. Hi ha tres tipus principals de portes:
- Porta d'Oblit (Forget Gate): Decideix quina informació de la memòria a llarg termini es descarta.
- Porta d'Entrada (Input Gate): Decideix quina informació nova s'emmagatzema a la memòria a llarg termini.
- Porta de Sortida (Output Gate): Decideix quina informació de la memòria a llarg termini s'utilitza per generar la sortida.
Arquitectura d'una Cèl·lula LSTM
Implementació d'una LSTM amb PyTorch
Importació de Llibreries Necessàries
Creació d'una Xarxa LSTM Simple
A continuació, crearem una xarxa LSTM simple per predir una seqüència de nombres.
class SimpleLSTM(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers=1):
super(SimpleLSTM, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
out, _ = self.lstm(x, (h0, c0))
out = self.fc(out[:, -1, :])
return outExplicació del Codi
__init__: Inicialitza la xarxa LSTM amb els paràmetres d'entrada, mida de la capa oculta, mida de la sortida i el nombre de capes.forward: Defineix el pas endavant de la xarxa. Inicialitza els estats ocults i de cèl·lula a zero, passa l'entrada a través de la capa LSTM i després a través d'una capa lineal per obtenir la sortida final.
Entrenament de la Xarxa LSTM
# Paràmetres
input_size = 1
hidden_size = 50
output_size = 1
num_layers = 1
num_epochs = 100
learning_rate = 0.01
# Dades d'exemple
x_train = np.array([[i] for i in range(100)], dtype=np.float32)
y_train = np.array([[i+1] for i in range(100)], dtype=np.float32)
x_train = torch.from_numpy(x_train).unsqueeze(0)
y_train = torch.from_numpy(y_train).unsqueeze(0)
# Model, pèrdua i optimitzador
model = SimpleLSTM(input_size, hidden_size, output_size, num_layers)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# Entrenament
for epoch in range(num_epochs):
model.train()
outputs = model(x_train)
optimizer.zero_grad()
loss = criterion(outputs, y_train)
loss.backward()
optimizer.step()
if (epoch+1) % 10 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')Explicació del Codi
- Dades d'exemple: Generem una seqüència de nombres per entrenar la xarxa.
- Model, pèrdua i optimitzador: Inicialitzem el model LSTM, la funció de pèrdua (MSE) i l'optimitzador (Adam).
- Entrenament: Entrenem la xarxa durant 100 èpoques, actualitzant els pesos en cada època i imprimint la pèrdua cada 10 èpoques.
Exercicis Pràctics
- Modifica la Xarxa LSTM: Canvia la mida de la capa oculta i el nombre de capes i observa com afecta el rendiment de la xarxa.
- Predicció de Sèries Temporals: Utilitza una sèrie temporal real (per exemple, dades de temperatura) per entrenar i avaluar la xarxa LSTM.
- Comparació amb RNN: Implementa una xarxa RNN simple i compara el seu rendiment amb la xarxa LSTM en la mateixa tasca.
Solucions als Exercicis
Exercici 1: Modificació de la Xarxa LSTM
# Paràmetres modificats hidden_size = 100 num_layers = 2 # Model amb paràmetres modificats model = SimpleLSTM(input_size, hidden_size, output_size, num_layers) # Resta del codi d'entrenament es manté igual
Exercici 2: Predicció de Sèries Temporals
# Exemple de dades de temperatura (substitueix amb dades reals)
temps_data = np.sin(np.linspace(0, 100, 1000)) # Dades sintètiques
x_train = np.array([[temps_data[i]] for i in range(999)], dtype=np.float32)
y_train = np.array([[temps_data[i+1]] for i in range(999)], dtype=np.float32)
x_train = torch.from_numpy(x_train).unsqueeze(0)
y_train = torch.from_numpy(y_train).unsqueeze(0)
# Model, pèrdua i optimitzador
model = SimpleLSTM(input_size, hidden_size, output_size, num_layers)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# Entrenament
for epoch in range(num_epochs):
model.train()
outputs = model(x_train)
optimizer.zero_grad()
loss = criterion(outputs, y_train)
loss.backward()
optimizer.step()
if (epoch+1) % 10 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')Exercici 3: Comparació amb RNN
class SimpleRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers=1):
super(SimpleRNN, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device)
out, _ = self.rnn(x, h0)
out = self.fc(out[:, -1, :])
return out
# Model RNN
model_rnn = SimpleRNN(input_size, hidden_size, output_size, num_layers)
# Resta del codi d'entrenament es manté igualConclusió
En aquesta secció, hem après sobre les Xarxes de Memòria a Llarg i Curt Termini (LSTM), la seva arquitectura i com implementar-les amb PyTorch. Les LSTM són molt poderoses per a tasques seqüencials i poden recordar informació durant períodes de temps més llargs que les RNN tradicionals. Hem vist com crear una xarxa LSTM simple, entrenar-la i comparar-la amb una RNN. A més, hem proporcionat exercicis pràctics per reforçar els conceptes apresos. En el següent tema, explorarem les Unitats Recurrents Gated (GRUs), una altra variant de les RNN.
PyTorch: De Principiant a Avançat
Mòdul 1: Introducció a PyTorch
- Què és PyTorch?
- Configuració de l'Entorn
- Operacions Bàsiques amb Tensor
- Autograd: Diferenciació Automàtica
Mòdul 2: Construcció de Xarxes Neuronals
- Introducció a les Xarxes Neuronals
- Creació d'una Xarxa Neuronal Simple
- Funcions d'Activació
- Funcions de Pèrdua i Optimització
Mòdul 3: Entrenament de Xarxes Neuronals
- Càrrega i Preprocessament de Dades
- Bucle d'Entrenament
- Validació i Prova
- Desament i Càrrega de Models
Mòdul 4: Xarxes Neuronals Convolucionals (CNNs)
- Introducció a les CNNs
- Construcció d'una CNN des de Zero
- Aprenentatge per Transferència amb Models Preentrenats
- Ajust Fi de les CNNs
Mòdul 5: Xarxes Neuronals Recurrents (RNNs)
- Introducció a les RNNs
- Construcció d'una RNN des de Zero
- Xarxes de Memòria a Llarg i Curt Termini (LSTM)
- Unitats Recurrents Gated (GRUs)
Mòdul 6: Temes Avançats
- Xarxes Generatives Adversàries (GANs)
- Aprenentatge per Reforç amb PyTorch
- Desplegament de Models PyTorch
- Optimització del Rendiment